

- 정렬알고리즘
정렬 알고리즘은 주어진 데이터 집합을 특정한 기준에 따라 순서대로 정렬하는 알고리즘이다.
- 어떻게 정렬할 수 있을까?

[선택정렬]
처리되지 않은 데이터 중에서 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복합니다.
이 알고리즘의 핵심 아이디어는 매번 정렬되지 않은 부분에서 최소값을 찾아서 앞으로 이동시키는 것입니다. 이를 통해 배열의 가장 작은 요소가 정렬 과정 중에 제 위치를 찾아가게 되고, 나머지 요소들도 동일한 원리로 정렬됩니다.
선택 정렬 동작 예시
[Step 0] 처리되지 않은 데이터 중 가장 작은 ‘0’을 선택해 가장 앞의 ‘7’과 바꾼다.

[Step 1] 처리되지 않은 데이터 중 가장 작은 ‘1’을 선택해 가장 앞의 ‘5’와 바꾼다.

[Step 2] 처리되지 않은 데이터 중 가장 작은 ‘2’를 선택해 가장 앞의 ‘9’와 바꾼다.

[Step 3] 처리되지 않은 데이터 중 가장 작은 ‘3’을 선택해 가장 앞의 ‘7’과 바꾼다.

이러한 과정을 반복하면 다음과 같이 정렬이 완료된다.
→ 가장 작은 것을 선택해서 앞으로 보내는 과정을 반복해서 수행하다 보면, 전체 데이터의 정렬이 이루어진다.

선택정렬 소스 코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(array)):
min_index = i
for j in range(i+1, len(array)):
if array[min_index] > array[j]:
min_index = j
array[i], array[min_index] = array[min_index], array[i]
print(array)[0 1 2 3 4 5 6 7 8 9]선택 정렬의 시간 복잡도
선택 정렬의 시간 복잡도는 O(n^2)로, 배열의 크기에 비례하여 비효율적입니다. 그러나 선택 정렬은 구현이 간단하고 이해하기 쉬우며, 정렬해야 할 요소의 수가 상대적으로 작을 때 유용할 수 있습니다.
- 선택 정렬은 N번 만큼 가장 작은 수를 찾아서 맨 앞으로 보내야 한다.
- 구현 방식에 따라서 사소한 오차는 있을 수 있지만, 전체 연산 횟수는 다음과 같다.
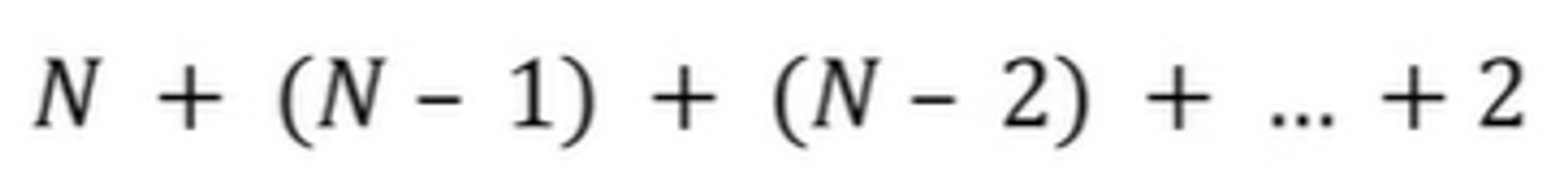
- 이는 (*N^*2+N+2)/2로 표현할 수 있는데, 빅오 표현법에 따라서 O(*N^*2)이라고 작성한다.
[삽입정렬]
삽입 정렬의 핵심 아이디어는 정렬된 부분 배열에 새로운 원소를 삽입하는 동안 정렬된 순서를 유지한다는 것입니다. 따라서, 배열이 이미 거의 정렬되어 있는 경우에는 효율적으로 동작하며, 작은 규모의 입력에 대해서도 성능이 좋습니다.
- 처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입한다.
- 선택 정렬에 비해 구현 난이도가 높은 편이지만, 일반적으로 더 효율적으로 동작한다.
삽입 정렬 동작 예시
[Step 0] 첫 번째 데이터 ‘7’은 그 자체로 정렬이 되어 있다고 판단하고, 두 번째 데이터인 ‘5’가 어떤 위치로 들어갈지 판단한다. ‘7’의 왼쪽으로 들어가거나 오른쪽으로 들어가거나 두 경우만 존재한다.

[Step 1] 이어서 ‘9’가 어떤 위치로 들어갈지 판단한다.

‘9’는 차례대로 왼쪽에 있는 데이터와 비교해서 왼쪽 데이터보다 더 작다면 위치를 바꿔 주고 그렇지 않다면 그냥 그 자리에 머물러 있도록 한다. ‘9’는 ‘7’보다 더 크기 때문에 현재 위치 그대로 내버려 둔다.
[Step 2] 이어서 ‘0’이 어떤 위치로 들어갈지 판단한다.

‘0’은 ‘9’, ‘7’, ‘5’와 비교했을 때 모두 작기 때문에 ‘5’의 왼쪽에 위치한다.
이러한 과정을 반복하면 다음과 같이 정렬이 완성된다.

삽입 정렬 소스코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j] < array[j-1]:
array[j], array[j-1] = array[j-1], array[j]
else:
break
print(array)[실행 결과]
[0,1,2,3,4,5,6,7,8,9]삽입 정렬의 시간 복잡도
삽입 정렬의 시간 복잡도는 최악의 경우에는 O(n^2)이며, 최선의 경우에는 O(n)입니다. 여기서 n은 배열의 크기를 나타냅니다. 또한, 삽입 정렬은 제자리 정렬(in-place sorting) 알고리즘이므로, 추가적인 메모리 공간을 필요로 하지 않습니다.
- 삽입 정렬의 시간 복잡도는 O(*N^*2)이며, 선택 정렬과 마찬가지로 반복문이 두 번 중첩되어 사용된다.
- 삽입 정렬은 현재 리스트의 데이터가 거의 정렬되어 있는 상태라면 매우 빠르게 동작한다.
최선의 경우 O(N)의 시간 복잡도를 가진다.
[퀵정렬]
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법이다.
- 일반적인 상황에서 가장 많이 사용되는 정렬 알고리즘 중 하나이다.
- 병합 정렬과 더불어 대부분의 프로그래밍 언어의 정렬 라이브러리의 근간이 되는 알고리즘이다.
- 가장 기본적인 퀵 정렬은 첫 번째 데이터를 기준 데이터(pivot)로 설정한다.
퀵 정렬 동작 예시
[Step 0] 현재 피벗의 값은 ‘5’이다. 왼쪽에서부터 ‘5’보다 큰 데이터를 선택하므로 ‘7’이 선택되고, 오른쪽에서부터 ‘5’보다 작은 데이터를 선택하므로 ‘4’가 선택된다.

[Step 1] 현재 피벗의 값은 ‘5’이다. 왼쪽에서부터 ‘5’보다 큰 데이터를 선택하므로 ‘9’가 선택되고, 오른쪽에서부터 ‘5’보다 작은 데이터를 선택하므로 ‘2’가 선택된다. 이제 이 두 데이터의 위치를 서로 변경한다.

[Step 0]현재 피벗의 값은 ‘5’이다. 왼쪽에서부터 ‘5’보다 큰 데이터를 선택하므로 ‘6’이 선택되고, 오른쪽에서부터 ‘5’보다 작은 데이터를 선택하므로 ‘1’이 선택된다. 단, 이처럼
위치가 엇갈리는 경우 ‘피벗’과 작은 데이터의 위치를 서로 변경한다.

[분할완료]이제 ‘5’의 왼쪽에 있는 데이터는 모두 5보다 작고, 오른쪽에 있는 데이터는 모두 ‘5’보다 크다는 특징이 있다. 이렇게 피벗을 기준으로 데이터 묶음을 나누는 작업을 분할(Divide)이라고 한다.

[왼쪽 데이터 묶음 정렬]왼쪽에 있는 데이터에 대해서 마찬가지로 정렬을 수행한다.

[오른쪽 데이터 묶음 정렬]오른쪽에 있는 데이터에 대해서 마찬가지로 정렬을 수행한다.

이러한 과정을 반복하면 전체 데이터에 대해서 정렬이 수행된다.
퀵 정렬이 빠른 이유: 직관적인 이해
- 이상적인 경우 분할이 절반씩 일어난다면 전체 연산 횟수로 O(NlogN)를 기대할 수 있다.
너비 X 높이 = N X logN = NlogN
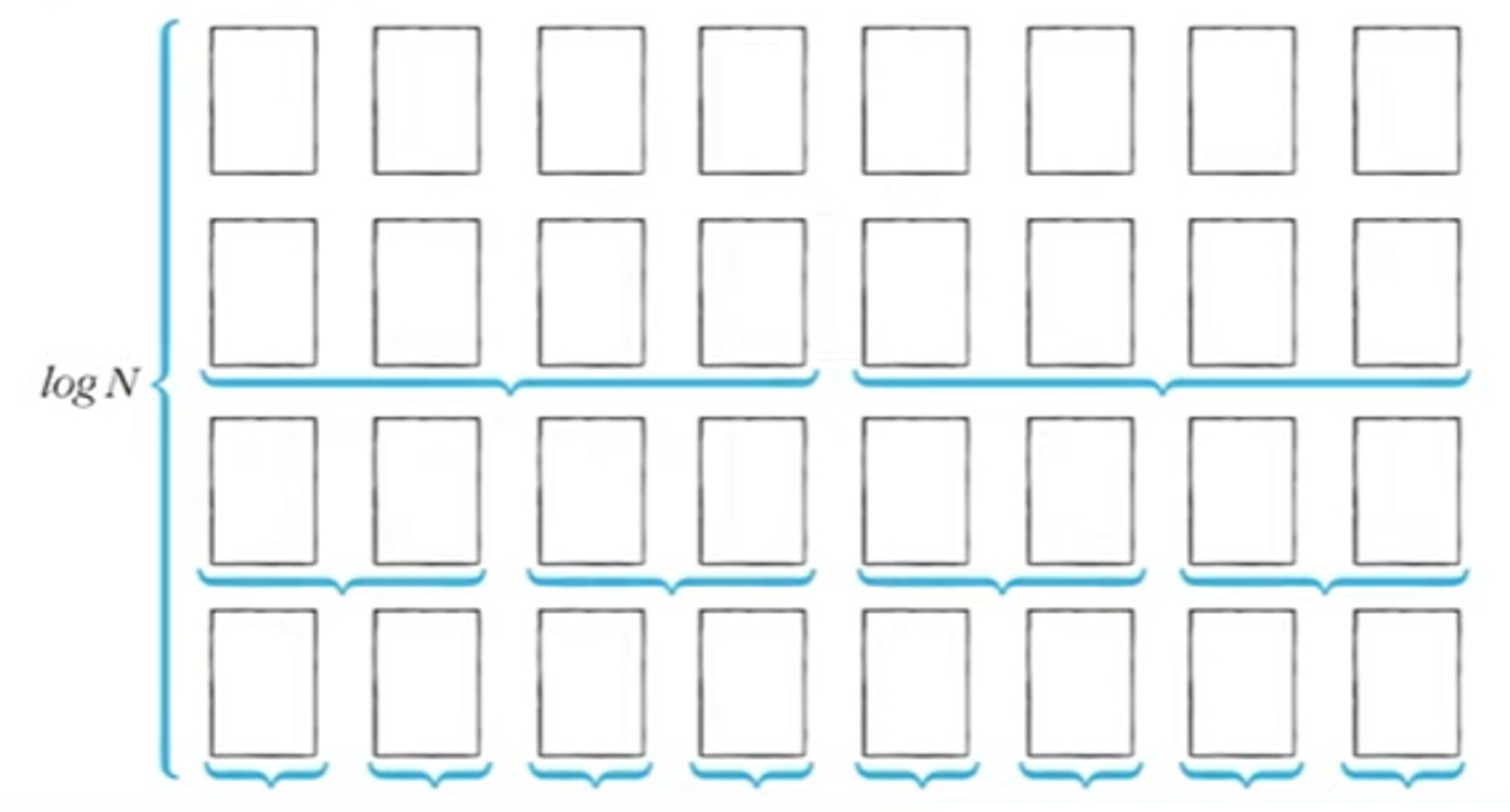
퀵 정렬의 시간 복잡도
퀵정렬은 평균적으로 O(n log n)의 시간 복잡도를 가지지만, 최악의 경우에는 O(n^2)의 시간 복잡도를 가질 수 있습니다. 최악의 경우는 피벗이 항상 최솟값 또는 최댓값으로 선택되는 경우에 발생합니다. 이러한 경우를 피하기 위해 피벗을 랜덤하게 선택하거나 중간값을 선택하는 방법 등을 사용할 수 있습니다.
- 퀵 정렬은 평균의 경우 O(NlogN)의 시간 복잡도를 가진다.
- 하지만 최악의 경우 O(N2)의 시간 복잡도를 가진다.
첫 번째 원소를 피벗으로 삼을 때, 이미 정렬된 배열에 대해서 퀵 정렬을 수행할 경우 최악의 경우이다.
- 표준 라이브러리를 사용하는 경우, 기본적으로 O(NlogN)을 보장한다.
array = [5,7,9,0,3,1,6,2,4,8]
def quick_sort(array, start, end):
if start >= end:
return
pivot = start
left = start + 1
right = end
while(left<=right):
while(left<=end and array[left]<=array[pivot]):
left += 1
while(right>start and array[right]>=array[pivot]):
right -= 1
if(left>right):
array[right], array[pivot] = array[pivot], array[right]
else:
array[left], array[right] = array[right], array[left]
quick_sort(array, start, right-1)
quick_sort(array, right+1, end)
quick_sort(array, 0, len(array)-1)
print(array)[실행 결과]
[0,1,2,3,4,5,6,7,8,9]문제 - 두 배열의 원소 교체
동빈이는 두 개의 배열 A와 B를 가지고 있다. 두 배열은 N개의 원소로 구성되어 있으며, 배열의 원소는모두 자연수이다
동빈이는 최대 K 번의 바꿔치기 연산을 수행할 수 있는데, 바꿔치기 연산이란 배열 A에 있는 원소 하나와배열 B에 있는 원소 하나를 골라서 두 원소를 서로 바꾸는 것을 말한다
동빈이의 최종 목표는 배열 A의 모든 원소의 합이 최대가 되도록 하는 것이며, 여러분은 동빈이를 도와야한다
N, K, 그리고 배열 A와 B의 정보가 주어졌을 때, 최대 K 번의 바꿔치기 연산을 수행하여 만들 수 있는배열 A의 모든 원소의 합의 최댓값을 출력하는 프로그램을 작성하라
예를 들어 N = 5, K = 3이고, 배열 A와 B가 다음과 같다고 해보자
- 배열 A = [1, 2, 5, 4, 3]
- 배열 B = [5, 5, 6, 6, 5]이 경우, 다음과 같이 세 번의 연산을 수행할 수 있다
- 연산 1) 배열 A의 원소 ‘1’과 배열 B의 원소 ‘6’을 바꾸기
- 연산 2) 배열 A의 원소 ‘2’와 배열 B의 원소 ‘6’을 바꾸기
- 연산 3) 배열 A의 원소 ‘3’과 배열 B의 원소 ‘5’를 바꾸기세 번의 연산 이후 배열 A와 배열 B의 상태는 다음과 같이 구성될 것이다
- 배열 A = [6, 6, 5, 4, 5]
- 배열 B = [3, 5, 1, 2, 5]이때 배열 A의 모든 원소의 합은 26이 되며, 이보다 더 합을 크게 만들 수는 없다
입력
- 첫 번째 줄: N, K 가 공백으로 구분되어 입력 (1 <= N <= 100,000, 0 <= K <= N)
- 두 번째 줄: 배열 A의 원소들이 공백으로 구분되어 입력 (원소 a < 10,000,000인 자연수)
- 세 번째 줄: 배열 B의 원소들이 공백으로 구분되어 입력 (원소 b < 10,000,000인 자연수)
출력
- 최대 K번 바꿔치기 연산을 수행해서 가장 최대의 합을 갖는 A의 모든 원소 값의 합을 출력
입력 예시
5 3
1 2 5 4 3
5 5 6 6 5출력 예시
26코드 구현
n, k = map(int, input().split())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
a.sort()
b.sort(reverse = True)
for i in range(k):
if a[i] < b[i]:
a[i], b[i] = b[i], a[i]
else:
break
print(sum(a))실행 결과
26